Zheng Gao

I work in the general field of Machine Learning, Data Science, and Statistics.
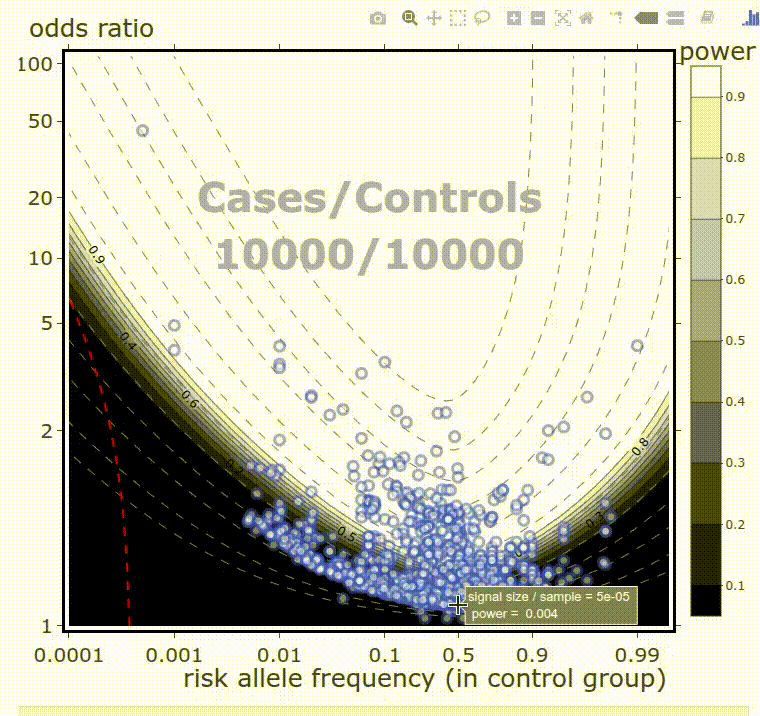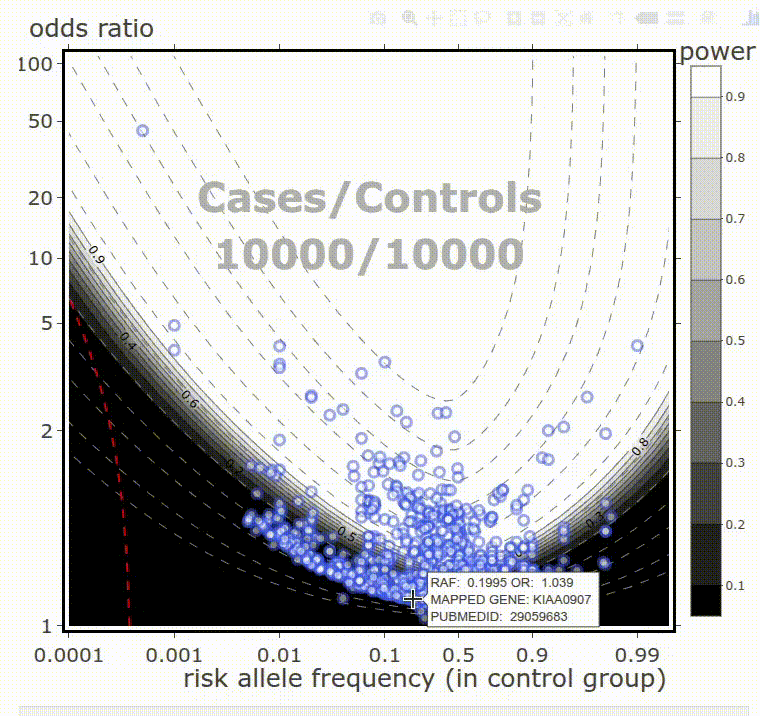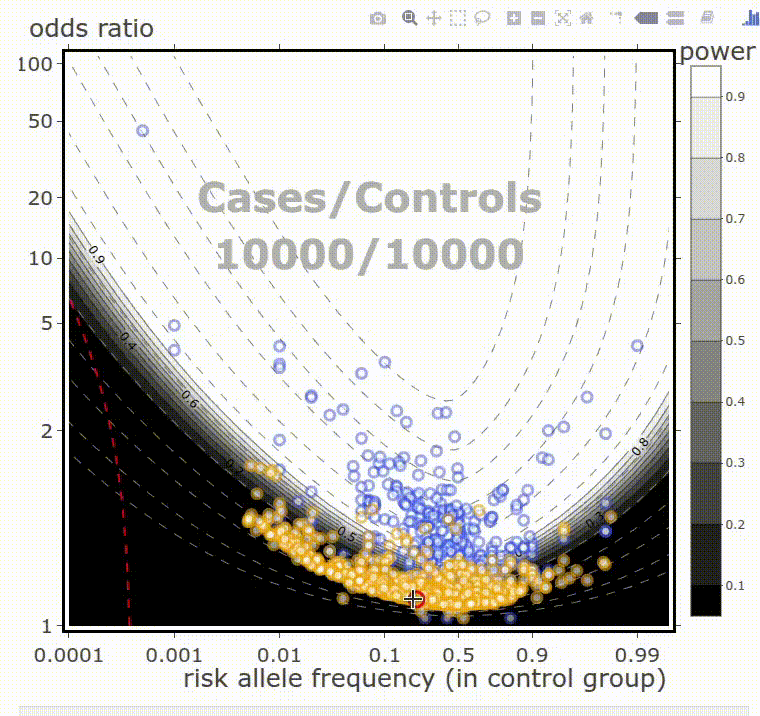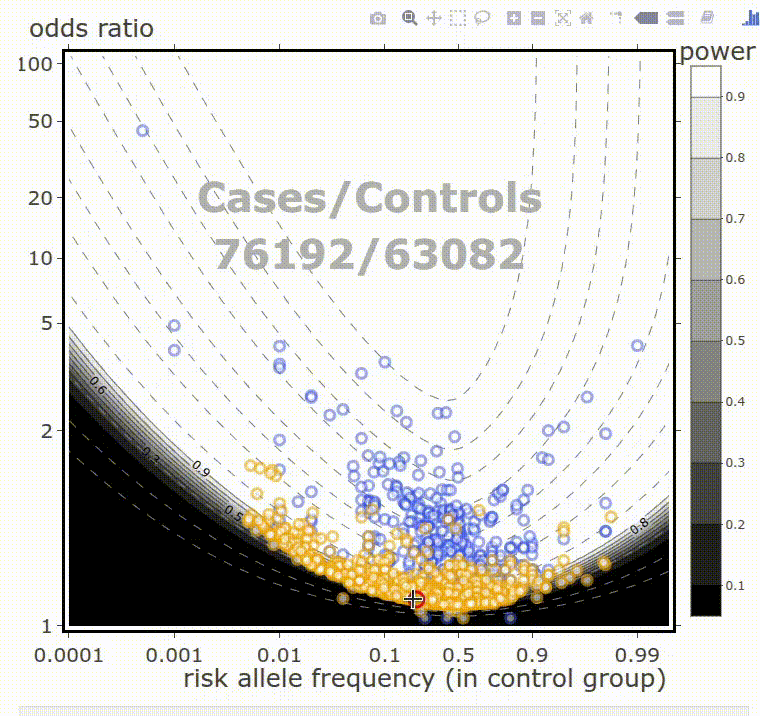
My inclination is applied. I develop and tune machine learning models for business applications. I also do analytical work. I wrote some web apps, enabling point-and-click data analyses.
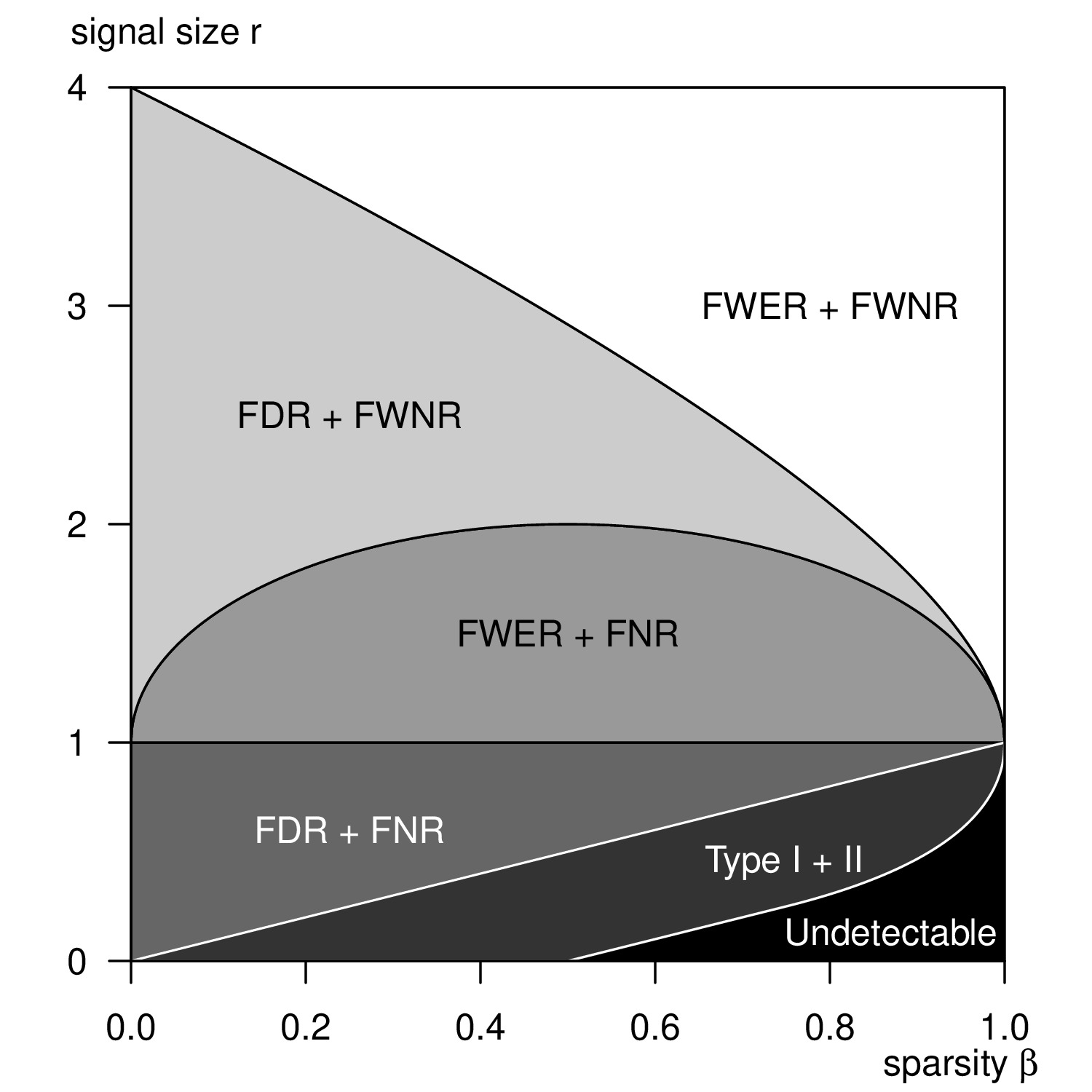
I did some work on statistical theory, and wrote a book on it. It was published as a SpringerBrief; see below.